What is Multipass?
▪ Renderpasses can have multiple subpasses.(렌더패스는 다수의 서브패스를 가질수 있다)
▪ Subpasses can have dependencies between each other(서브패스는 서로 디펜던시를 가질수 있다)
▪ Render pass graphs
▪ Subpasses refer to subset of attachments1 (서브패스는 attachment의 하위 집합을 나타낸다)

Improved MRT deferred shading in Vulkan
▪ Classic deferred has two render passes(전통적인 디퍼드는 두개의 렌더 패스를 가진다)
▪ G-Buffer pass, render to ~4 textures
▪ Lighting pass, read from G-Buffer, accumulate light(라이트를 모아서 처리)
▪ Lighting pass only reads G-Buffer at gl_FragCoord(라이팅 패스는 오직 gl_FragCoord(픽셀정보)에서 GBuffer만을 읽는다)
▪ Rethinking this in terms of Vulkan multipass(불칸의 멀티패스 측면에서 다시 생각하기)
▪ Two subpasses
▪ Dependencies
▪ COLOR | DEPTH -> INPUT_ATTACHMENT | COLOR | DEPTH_READ
▪ VK_DEPENDENCY_BY_REGION_B2
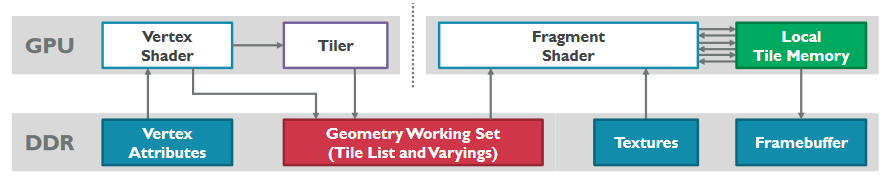
Tile-based GPUs 101
▪ Tile-based GPUs batch up and bin all primitives in a render pass to tiles(타일 기반 GPU는 렌더패스의 모든 프리미티브를 일괄 처리하고 타일에 저장)
▪ In fragment processing later, render one tile at a time(추후 프래그먼트를 처리시 한타일씩 렌더링)
▪ Hardware knows all primitives which cover a tile(하드웨어는 타일을 덮는 모든 프리미티브를 알고 있다)
▪ Advantage, framebuffer is now in fast and small SRAM!(장점은 프레임 버퍼는 이제 빠르고 작은 SRAM에 있다)
▪ Having framebuffer in on-chip SRAM has practical benefits(온칩의 SRAM에 프레임 버퍼가 있으면 실용적인 이점이 있음)
▪ Read/write to it is cheap, no external bandwidth cost(읽기/쓰기 비용이 저렴하고 추가적인 대역폭 비용이 들지 않음)
▪ Main memory is written to when tile is complete(타일이 완성되면 메인 메모리에 기록)
Tile-based GPU subpass fusing
▪ Subpass information is known ahead of time
▪ VkRenderPass
▪ Driver can find two or more sub-passes which have ...(드라이버는 두개 혹은 그 이상은 서브패스를 가지고 있는지를 찾을수 있다)
▪ BY_REGION dependencies
▪ no external side effects which might prevent fusing(통합을 방해하는 추가적인 사이드 이펙트는 없음)
▪ Fuse G-Buffer and Lighting passes(GBuffer와 라이팅 패스를 통합)
▪ Combine draw calls from G-Buffer and Lighting into one “render pass”(GBuffer 와 라이팅의 드로우콜을 하나의 렌더패스로 통합)
▪ G-Buffer content can remain in on-chip SRAM(GBuffer의 내용이 온칩 SRAM에 남을수 있음)
▪ Reading G-Buffer data in lighting pass just needs to read tile buffer(라이팅 패스의 Gbuffer의 데이터 읽기는 타일 버퍼에서 읽기만 하면 된다)
▪ vkCmdNextSubpass essentially becomes a noop(vkCmdNextSubpass는 필수적으로 쓰이지 않게 된다)

Vulkan GLSL subpassLoad()
▪ Reading from input attachments in Vulkan is special
▪ Special image type in SPIR-V3
▪ On vkCreateGraphicsPipelines we know
▪ renderPass
▪ subpassIndex
▪ subpassLoad() either becomes(서브패스로드()는 다음중 하나가 된다)
▪ texelFetch()-like if subpasses were not fused(만약에 서브패스가 통합되지 않으면 texelFetch()처럼 된다)
▪ This is why we need VK_DESCRIPTOR_TYPE_INPUT_ATTACHMENT(이것이 VK_DESCRIPTOR_TYPE_INPUT_ATTACHMENT이 필요한 이유)
▪ magicReadFromTilebuffer() if subpasses were fused(서브패스가 통합된 경우 magicReadFromTilebuffer())
▪ Compiler knows ahead of time(컴파일러는 미리 알고 있음)
▪ No last-minute shader patching required(마지막에 셰이더 패치가 필요하지 않음)
Transient attachments(임시 Attachments)
▪ After the lighting pass, G-Buffer data is not needed anymore(라이팅 패스후 Gbuffer 데이터는 더이상 필요하지 않음)
▪ G-Buffer data only needs to live on the on-chip SRAM(Gbuffer data는 온칩SRAM에만 존재하면 됨)
▪ Clear on render pass begin, no need to read from main memory(렌더 패스 시작시 지우고 메인메모리에서 읽을 필요없음)
▪ storeOp is DONT_CARE, so never actually written out to main memory(storeOp는 DONT_CARE이므로 실제 주 메모리에 기록되지 않음)
▪ Vulkan exposes lazily allocated memory(불칸은 지연할당된 메모리를 노출한다)
▪ imageUsage = VK_IMAGE_USAGE_TRANSIENT_ATTACHMENT_BIT
▪ memoryProperty = VK_MEMORY_PROPERTY_LAZILY_ALLOCATED_BIT
▪ On tilers, no need to back these images with physical memory ☺(타일러에서는 이 이미지를 물리적으로 백업할 필요가 없음)
Multipass benefits everyone
▪ Deferred paths essentially same for mobile and desktop(디퍼드 패스는 모바일과 데스크탑에서 기본적으로 동일)
▪ Same Vulkan code (*)
▪ Same shader code (*)
▪ VkRenderPass contains all information it needs
▪ Desktop can enjoy more informed scheduling decisions(데스크탑은 더 많은 정보에 입각한 스케쥴링 결정이 가능하다)
▪ Latest desktop GPU iterations seem to be moving towards tile-based(최신 데스크탑 GPU는 점점 타일 기반으로 바뀌는중)
▪ At worst, it’s just classic MRT(최악은 그냥 전형적인 MRT4
▪ (*) Minor tweaking to G-Buffer layout may apply(Gbuffer 레이아웃에 약간의 트윅이 적용될 수 있음)

Baseline test
▪ Basic multipass sample
▪ One renderpass
▪ Light on geometry
▪ ~8 large lights
▪ Simple shading
▪ Benchmark
▪ Multipass (subpass fusing)
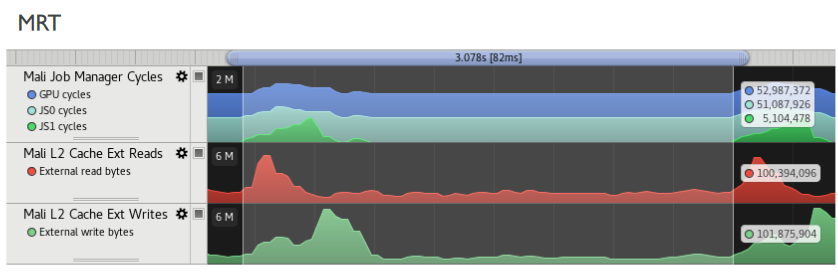
▪ MRT
▪ Overall performance
▪ Bandwidth

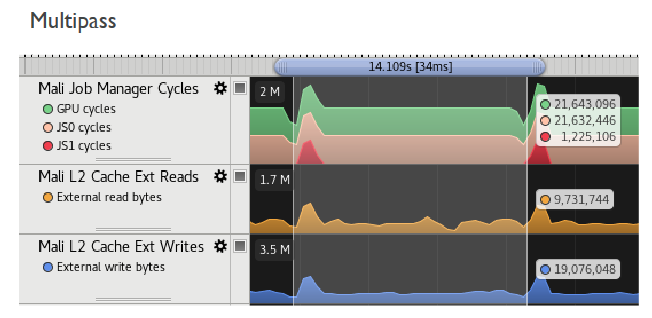
Baseline test data
▪ Measured on Galaxy S7 (Exynos)
▪ 4096x2048 resolution
▪ Hit V-Sync at native 1440p
▪ ~30% FPS improvement
▪ ~80% bandwidth reduction
▪ Only using albedo and normals
▪ Saving bandwidth is vital for mobile GPUs(대역폭 절약은 모바일에서 필수적)

Sponza test
▪ Mid-high complexity geometry for mobile
▪ ~200K tris drawn / frame
▪ ~610 spot lights
▪ Full PBR
▪ Shadowmaps on some of the lights
▪ 8 reflection probes
▪ Directional light w/ shadows
▪ Full HDR pipeline
▪ Adaptive tonemapping
▪ Bloom




Clustered stencil culling
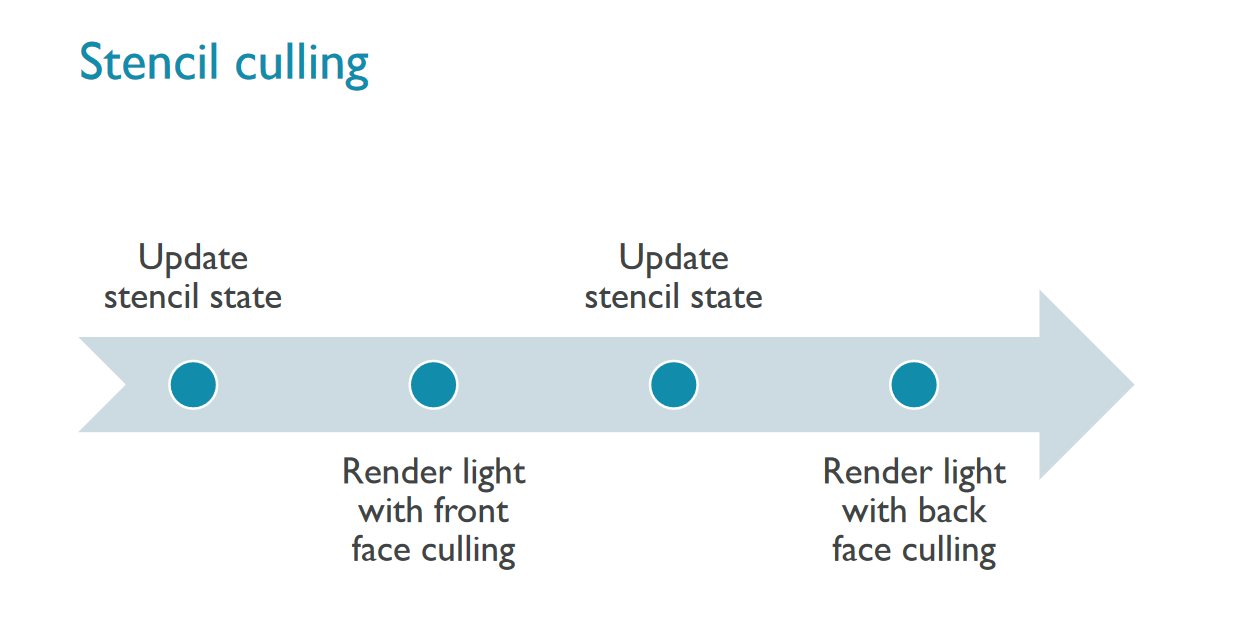
▪ Classic method of per light stencil culling involves a lot of state toggling(라이트 스텐실 컬링의 고전적인 방법은 많은 상태 토글을 포함)
▪ Can be expensive even on Vulkan(심지어 불칸에서도 비쌈)
▪ Usually performs poorly on GPU(일반적인 GPU에서 성능이 좋지 않음)
▪ Instead, cluster local lights along camera Z axis(대신 카메라 Z축(깊이)을 따라 로컬 라이트를 클러스터링한다)
▪ Each light is assigned to a cluster using conservative depth(각 조명은 전통적인 뎁스를 사용하여 클러스터에 할당)
▪ Stencil is written for all local lights in a single pass( 스텐실은 단일 패스에서 모든 로컬 조명에 대해 작성)
▪ Peel depth for an extra 2-bit “depth buffer” in stencil(스텐실에서 추가 2비트 "뎁스버퍼"를 위한 뎁스제거)
▪ Lights are finally rendered using stencil with double sided depth test(라이트들은 투사이드 뎁스 테스트와 함께 스텐실을 사용하여 최종적으로 렌더)

Sponza test data
▪ Far, far heavier than sensible mobile content
▪ 1440p (native)
▪ Overkill
▪ ~50-60% bandwidth reduction
▪ ~18% FPS increase

<<Lofoten»
▪ City scene with ~2.5 million primitives(도시씬은 250만개의 프리미티가 존재)
▪ Relies heavily on CPU based culling techniques to reduce geometry load(지오메트리 로드를 줄이기 위해 CPU 기반 컬링 테크닉에 크게 의존)
▪ 100 spot lights and point lights w/shadow maps
▪ Reflection probes
▪ Sun light with cascaded shadow maps
▪ Atmospheric scattering
▪ Ocean simulation
▪ FFT5 running GPU compute
▪ Separate refraction pass(분리된 굴절패스)
▪ Screen space reflections
▪ Bloom post-processing w/adaptive luminance tone mapping(적응형 휘도 톤 매핑 포함)
Not your typical mobile graphics pipeline

Implementation details
▪ G-buffer pass
▪ On tile-based GPUs, fill rate != bandwidth(타일베이스 GPU에서는 대역폭과 fill rate가 같지 않음)
▪ Emissive/forward materials written directly to light buffer(emissive/forward 매터리얼은 직접 라이트 버퍼에 기록)
▪ Stencil set to mark reflection influence(반사에 영향을 표시하도록 설정된 스텐실)
▪ Depth peeling for clustered stencil culling(클러스터링된 스텐실 컬링을 위한 뎁스 제거)
▪ Lighting pass
▪ Lighting accumulated using additive blending to lighting attachment(조명 어태치먼트에 additive 블렌딩을 사용해 라이팅 을 취합)
▪ Clustered stencil culling used for local lights(클러스터 스텐실 컬링은 로컬라이트 컬링에 사용됨)
▪ Transparent objects
▪ Fog applied after shading is complete(셰이딩 완료후 안개적용)
▪ Only commits light buffer to memory(라이트 버퍼만 메모리에 커밋)
Render passes
▪ Early decision to also make the high level interface explicit in terms of defining render passes(렌더 패스를 정의하는 과정에서 높은 수준의 인터페이스를 명시적으로 만들기 위한 조기 결정)
- Possible to back-port to OpenGL etc
▪ BeginRenderPass()
NextSubPass()
EndRenderPass()
Integration for transient and lazy images(일시적이자 지연된 이미지의 통합)
▪ Add support for “virtual” attachments(가상 어태치먼트 지원 추가)
▪ Keep a pool of images allocated with TRANSIENT_ATTACHMENT_BIT(TRANSIENT_ATTACHMENT_BIT로 할당된 이미지 풀을 유지)
▪ Actual image handles not visible to the API user(실제 이미지 핸들은 사용자 API에서 표시되지 않음)
| multipass.virtualAttachments = { RGBA8, RGBA8, RGB10A2 }; mutipass.numSubpasses = 2; multipass.subpass[0].colorTargets = { RT0, VIRTUAL0, VIRTUAL1, VIRTUAL2 }; multipass.subpass[1].colorTargets = { RT0 }; multipass.subpass[1].inputs = { VIRTUAL0, VIRTUAL1, VIRTUAL2, DEPTH }; renderpass.multipass = &multipass; BeginRenderPass(&renderpass); |
Multipass – virtual attachments
| // Render G-buffer pCB->BeginRenderPass(pCommandBuffer, KINSO_RENDERPASS_LOAD_CLEAR_ALL | KINSO_RENDERPASS_STORE_COLOR, Vec4(0.0f), 1.0f, 0, &m_Multipass); DrawGeometry(); // Increment to the next subpass. pCB->NextSubpass(); // Render lights additively. DrawLightGeometry(); // Finally apply environment effects ApplyEnv(); pCB->EndRenderPass(); |
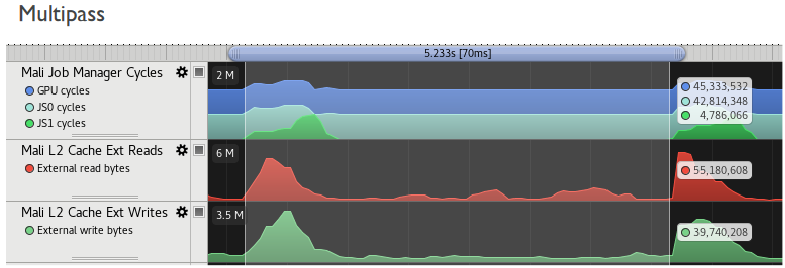
«Lofoten» test data
▪ Even heavier than Sponza
▪ 1440p (native)
▪ Overkill
▪ ~50% bandwidth save
▪ ~12% FPS increase
▪ ~25% GPU energy save!



Performance considerations for tilers
▪ With on-chip SRAM, per-pixel buffer size is limited(온칩 SRAM을 사용하면 픽셀당 버퍼 크기가 제한됨)
▪ G-Buffer size is therefore limited(따라서 GBuffer 사이즈가 제한됨)
▪ On current Mali hardware, 128 bits color targets per pixel(현재 Mali 하드웨어에서 픽셀당 128bit 컬러타겟)
▪ May vary between GPUs and vendors(GPU 벤더에 따라 다를수 있음)
▪ Smaller tiles may allow for larger G-Buffer(더 작은 타일은 더 큰 GBuffer를 허용할 수 있음)
▪ At a quite large performance penalty(상당히 큰 성능 저하)
▪ Fewer threads active, worse occupancy on shader core(활성 쓰레드 수가 적고, 셰이더 코어 점유율이 떨어짐)
▪ Need to scan through tile list more(타일 리스트를 좀 더 살펴봐야 함)
Engine integration for multiple APIs
▪ Render pass concept in engine is a must(엔진의 렌더 패스 개념은 필수)
▪ Cannot express multiple subpasses otherwise(그렇지 않다면 여러 서브 패스를 표현하기 어려움)
▪ subpassLoad() is unique to Vulkan GLSL(subpassLoad()는 Vulkan GLSL의 특징)
▪ Solution #1,Vulkan GLSL is main shading language(솔루션 #1, Vulkan GLSL은 주 셰이딩 언어)
▪ SPIRV-Cross can remap subpassLoad() to MRT-style texelFetch( SPIRV-Cross는 subpassLoad()를 MRT 스타일의 texelFetch로 다시 매핑할 수 있음)
▪ Solution #2, HLSL or similar(솔루션 #2, HLSL 또는 이와 비슷한것)
▪ Make your own “intrinsic” which emits subpassLoad in Vulkan(Vulkan에서 subpassLoad를 내보내는 고유한 "intrinsic-내부" 만들기)
▪ Unroll multipass to multiple passes in other APIs(다른 API에서 다수의 패스를 여러 패스로 해제)
▪ Change render targets on NextSubpass()(NextSubpass()에서 렌더 타겟 변경)
▪ Bind input attachments for subpass to texture units(서브패스에 대한 input attachment를 텍스처 단위에서 바인딩)
▪ Statically remap input_attachment_index -> texture unit in shader(input_attachment_index -> 셰이더의 텍스처 단위를 정적으로 다시 매핑)
Handling image layouts
▪ G-Buffer images are by design only used temporarily(G-Buffer 이미지는 일시적으로만 사용하도록 설계)
▪ No need to track layouts(레이아웃을 추적할 필요 없음)
▪ Application should not have direct access to these images!(애플리케이션은 이러한 이미지에 직접 액세스할 수 없어야 한다)
▪ Can use external subpass dependencies for transition(전환을 위해 외부 서브패스 종속성을 사용할 수 있다.)
| VkSubpassDependency dep = {}; dep.srcSubpass = VK_SUBPASS_EXTERNAL; dep.dstSubpass = 0; attachment.initialLayout = VK_IMAGE_LAYOUT_UNDEFINED; reference.layout = VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL; dep.srcAccessMask = COLOR_ATTACHMENT_WRITE; dep.dstAccessMask = COLOR_ATTACHMENT_READ | WRITE; dep.srcStageMask = COLOR_ATTACHMENT_OUTPUT; dep.dstStageMask = COLOR_ATTACHMENT_OUTPU |
- 이미지는 레이아웃, 형식 등에 대한 메타데이터가 있는 메모리 조각일 뿐으로, 프레임 버퍼는 용도(usage), 식별자(index) 및 유형(color, depth 등)과 같은 각 이미지에 대한 추가 메타데이터가 있는 여러 이미지의 모음(container)이다. 프레임 버퍼에서 사용되는 이러한 이미지는 프레임 버퍼에 첨부(attachment)되고 소유되기 때문에 attachment라고 한다.
렌더링되는 attachment를 렌더 타겟이라고 하고, 입력으로 사용되는 attachment를 Input attachment라고 한다.
Multisampling에 대한 정보를 담고 있는 attachment를 Resolve Attachments라고 한다.
RGB/Depth/Stencil 정보가 있는 첨부 파일을 각각 Color/Depth/Stencil Attachments라고 한다.
https://www.reddit.com/r/vulkan/comments/a27cid/what_is_an_attachment_in_the_render_passes/ [본문으로] - https://developer.samsung.com/galaxy-gamedev/resources/articles/usage.html [본문으로]
- Vulkan의 셰이더 언어. https://blog.naver.com/dmatrix/221826523428 [본문으로]
- Multi Render Target https://mkblog.co.kr/gpu-multiple-render-targets-mrt/ [본문으로]
- 고속 푸리에 변환 https://blog.naver.com/PostView.naver?blogId=kks227&logNo=221633584963&parentCategoryNo=&categoryNo=299&viewDate=&isShowPopularPosts=true&from=search [본문으로]
'Technical Report > Graphics Tech Reports' 카테고리의 다른 글
| [번역]동적 변경을 가능하게 하는 Cyllista Game Engine의 오픈 월드를 위한 프로시저 배경 제작 도구 및 그리기 기능 (0) | 2022.07.04 |
|---|---|
| Marvelous Designer(마블러스 디자이너)란? (0) | 2022.06.26 |
| Marschner 반사 모델 (0) | 2022.03.23 |
| GDC 2022 Unity session list. (0) | 2022.03.16 |
| [번역]Disney Principled BSDF (0) | 2022.03.02 |
