원문 링크 : https://coburggraphicslab.github.io/files/Kuth25GWG.pdf
AMD link : https://gpuopen.com/learn/gpu-work-graphs/gpu-work-graphs-intro/?fbclid=IwY2xjawMmIAdleHRuA2FlbQIxMQABHvl4MRxkz6uzfhsgcnV6SgLYsQZoHE3HDRoOOCj6KsiYqLPplTJ3GkFz1yWC_aem_0q3oWG-YVfEeWqZ8Q2ZhKw



오늘 SIGGRAPH에서 Work Graphs에 대한 강좌를 진행합니다.
코부르크 대학교와 AMD는 2023년 1월부터 바이에른 주의 지원을 받아 Work Graphs의 실질적인 연구에 공동으로 집중해 왔습니다.
지난 2년 반 동안 Work Graphs는 우리의 업무 환경을 지배해 왔으며, 이 새로운 기술을 활용하여 저희와 다른 연구자들이 지금까지 무엇을 했는지 간략하게 말씀드리고자 합니다.

우리가 연구를 진행하는 동안 Work Graphs는 샘플 코드가 포함된 미리보기로 제공되었고, Vulkan 지원이 추가되었으며, AMD는 여러 개의 Work Graphs 샘플을 게시했습니다.
Work Graphs Preview
https://gpuopen.com/learn/gpu-work-graphs/gpu-work-graphs-intro/
▪ Sample Code
https://github.com/GPUOpen-LibrariesAndSDKs/WorkGraphsHelloWorkGraphs
▪ Vulkan Support
https://gpuopen.com/gpu-work-graphs-in-vulkan/
▪ Work Graph Samples
https://gpuopen.com/learn/rgp-work-graphs/
https://gpuopen.com/learn/work_graphs_learning_sample/

게임 개발자 컨퍼런스(GDC) 2024에서 Work Graphs를 활용한 첫 데모를 선보였습니다. 또한, 연구 결과를 고성능 그래픽(HPG) 2024에 발표했습니다.
GDC 2024 - GPU Work Graphs: Welcome to the Future of GPU Programming
https://youtu.be/QQP6-JF64DQ?si=s1CA8AIouDfdZYom
GDC 2024 We reveal incredible Work Graphs perf, AMD FSR 3.1, GI with Brixelizer, and so much more
https://gpuopen.com/events/amd-at-gdc-2024/
GDC 2024 Work graphs and draw calls – a match made in heaven!
https://gpuopen.com/learn/gdc-2024-workgraphs-drawcalls/
Real-Time Procedural Generation with GPU Work Graphs
https://gpuopen.com/download/Real-Time_Procedural_Generation_with_GPU_Work_Graphs-GPUOpen_preprint.pdf
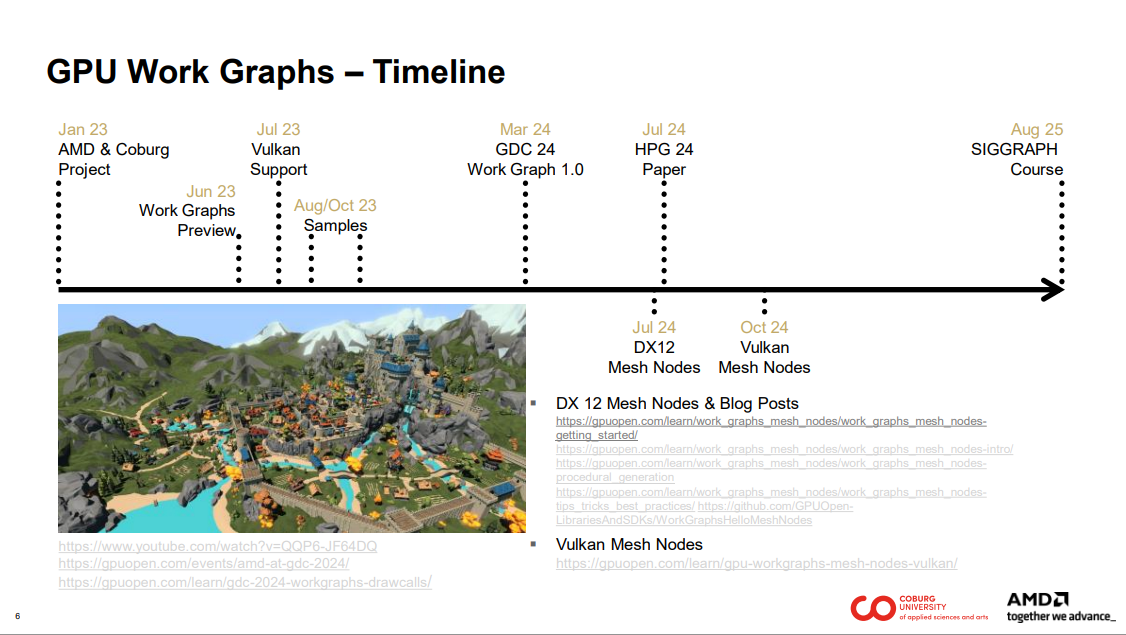
저희 연구는 2024년 3분기에 출시된 메시 노드를 활용합니다. 또한 works graph와 mesh node에 대한 내용을 담은 여러 블로그 게시물을 작성했습니다.1
웍스 그래프의 장점을 강조하는 데모 영상은 여기에서 확인하실 수 있습니다.
https://gpuopen.com/learn/gdc-2024-workgraphs-drawcalls/

GDC 데모와 HPG 논문이 많은 관심을 불러일으켜 2024년 네덜란드 브레다에서 열리는 그래픽 프로그래밍 컨퍼런스 마스터 클래스에 초청받았습니다. 바로 이 자리에서 Work Graph Playground 앱을 처음 출시했습니다. 이 수업에서도 이 앱을 사용할 예정입니다. 노트북을 가져오셨다면 Work Graph Playground 앱을 직접 사용해 보실 수 있습니다.

앱을 바이너리로 설치하려면 다음 단계를 따르세요. 지금 바로 설치하시기 바랍니다. 약 30분 후에 앱을 사용해 보세요.
GPU가 Work Graphs를 지원하지 않는 경우, WARP(소프트웨어 에뮬레이션) 어댑터를 사용하세요. DownloadWarpAdapter.bat 배치 스크립트를 사용하여 해당 DLL을 다운로드하세요.
GitHub 저장소의 지침에 따라 소스 코드에서 빌드할 수도 있습니다.
https://github.com/GPUOpen-LibrariesAndSDKs/WorkGraphPlayground
https://github.com/GPUOpen-LibrariesAndSDKs/WorkGraphPlayground/releases

앱 외에도 GDC 2025를 위해 Work Graphs를 사용하여 GPU에서 직접 식물을 생성하는 데모도 만들었습니다.

저희 데모에는 몇 주 전 HPG 2025에서 공유할 수 있었던 연구 결과가 가득합니다.
HPG에서 Bastian의 강연 영상은 여기에서 시청하실 수 있습니다: https://www.youtube.com/watch?v=SPWDLMc-9h4&t=26050s
전체 논문은 여기에서 확인하실 수 있습니다: https://diglib.eg.org/bitstream/handle/10.2312/hpg20251168/hpg20251168.pdf
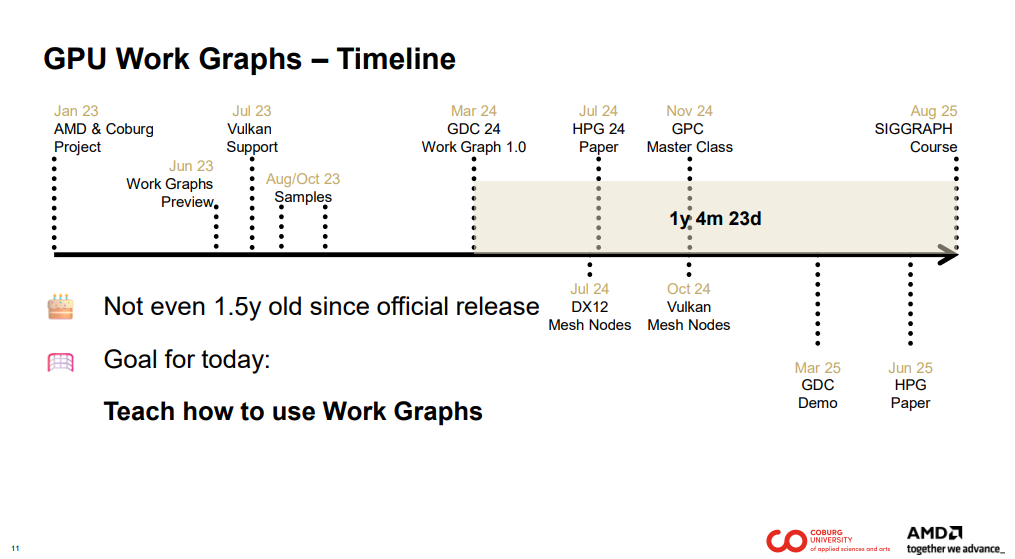
6월에는 미리보기 단계를 포함하여 Work Graphs 출시 2주년을 기념했습니다. Work Graphs가 공식 발표된 지 1년 반도 채 되지 않았습니다. 따라서 상당히 새로운 기술입니다.
이 과정의 목표는 여러분께 Work Graphs의 사용법을 알려드리고, 이를 여러분의 애플리케이션에 직접 활용할 수 있도록 돕는 것입니다.

오늘 다룰 주제에 대한 간략한 개요는 다음과 같습니다.

Work Graphs의 강력한 기능을 보여주는 몇 가지 애플리케이션을 살펴보았습니다. 자세한 내용을 살펴보기 전에 먼저 핵심 질문부터 답해 보겠습니다.
왜 Work Graphs를 사용해야 할까요?
이 질문에는 다른 접근 방식과 Work Graphs를 왜 선호해야 하는지에 대한 질문이 뒤따릅니다. 하지만 그 전에 Work Graphs에 중요한 GPU 개념을 간략하게 살펴보겠습니다.

우리는 이러한 개념이 Work Graphs에 중요하다고 믿습니다.

2002년 DirectX 9.0 Shader Model 2.0은 최초의 프로그래밍 가능 하드웨어 정점 및 픽셀 셰이더 파이프라인으로 간주됩니다. 2년 후, Shader Model 3.0은 동적 제어 흐름을 추가했습니다[Akenine-Möller 2018].
지오메트리 셰이더[Blythe 2006]는 프로그래밍 가능한 프리미티브별 처리를 선보였습니다. 하드웨어 테셀레이션[Andrews and Barker 2006]은 빠른 온-칩(on-chip) 지오메트리 증폭[Niessner et al. 2016]을 가능하게 했습니다.
컴퓨트 셰이더[Peercy et al., Nvidia 2007]의 도입은 하드웨어 지향 프로그래밍 모델, 즉 GPGPU의 시작을 드러냈습니다. GPU Gems 3 책[Nguyen 2007]에서 볼 수 있듯이, 이를 통해 GPU는 고성능 그래픽 및 비그래픽 애플리케이션을 실행할 수 있게 되었습니다. 또한, 하드웨어에서의 최신 GPU 레이 트레이싱[Haines and Akenine-Möller 2019]은 컴퓨트 셰이더 기반 레이 트레이싱 구현[Parker et al. 2010]에서 유래했습니다.
indirect execution 또는 execute indirect 2를 통해 드로우 콜과 디스패치의 크기를 GPU 메모리에서 가져와 GPU 기반 작업 생성을 가능하게 합니다. 증폭(Amplification)3 및 메시 셰이더[Kubisch 2018]는 컴퓨트 셰이더의 프로그래밍 모델을 따라 래스터화 워크로드를 위한 단일 레벨의 비재귀적 증폭 파이프라인을 제공합니다.
Works Graph[Microsoft 2024]는 컴퓨팅 및 래스터화 워크로드의 다단계 자체 재귀적 증폭을 제공하여 GPU 프로그래밍 가능성을 높입니다.4

우리는 이러한 이정표가 GPU 파이프라인의 기본 개념을 설명하기에 충분하다고 생각합니다.

…그리고 프로그래밍 가능한 정점 및 픽셀 셰이딩을 도입한 Shader Model 2부터 시작합니다.
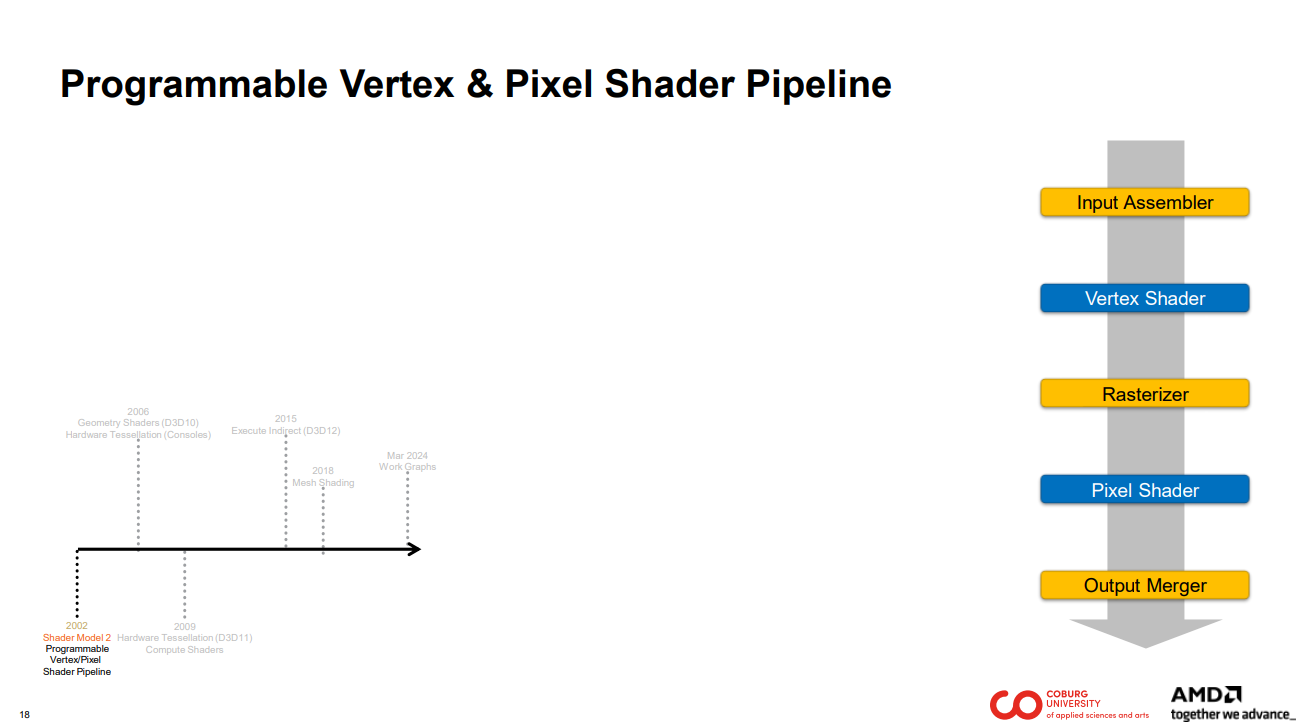
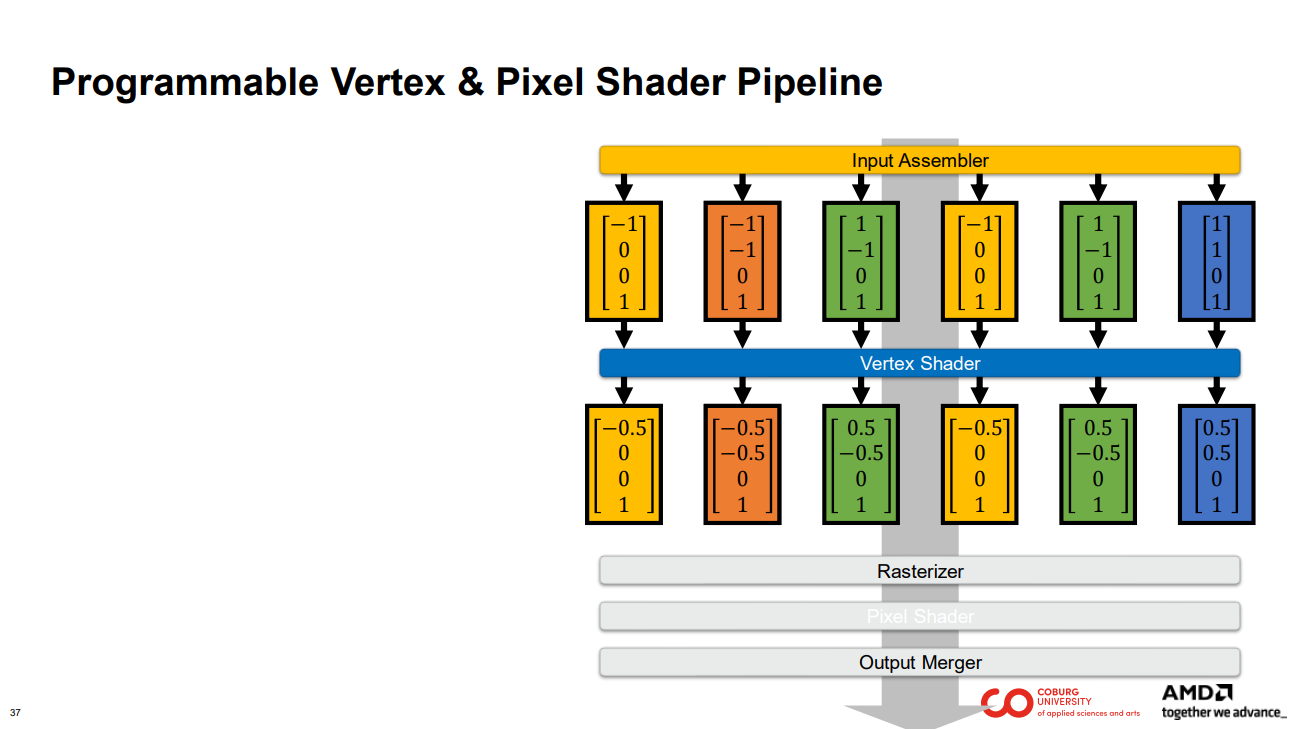
파이프라인을 간략하게 표현한 버전입니다. 파란색과 노란색 상자는 파이프라인의 각 단계를 나타냅니다.

원으로 표시된 꼭짓점을 가진 삼각형 메시가 주어졌습니다. 검은색 모서리는 꼭짓점을 연결하여 삼각형을 형성합니다. 꼭짓점 좌표는 열 벡터로 표시된 4D 좌표입니다.
이들은 오른쪽에 보여지는 표시된 파이프라인에 입력됩니다
output으로 슬라이드 왼쪽 하단의 픽셀 그리드에 표시된 것처럼 픽셀 그래픽을 얻습니다.

정점(vertex) 좌표는 vertex buffer라 불리는 배열에 저장됩니다.

그리고 vertex index는 index buffer라고 불리는 곳에 저장됩니다.

파이프라인에 정점 버퍼와 인덱스 버퍼를 입력하면 어떤 일이 일어나는지 다시 살펴보겠습니다.
먼저, 인덱스 버퍼의 각 요소가 input assembler에 입력됩니다.

그런 다음 인풋 어셈블러는 정점 버퍼에서 요소(elements, 여기서는 vertex 내의 값들)를 수집하여 outputs에서 사용할 수 있도록 합니다.

인풋 어셈블러는 각 요소를 독립적으로 처리할 수 있습니다. 이를 통해 GPU는 높은 수준의 병렬성을 확보할 수 있습니다.

그런 다음 정점은 다음 단계인 정점 셰이더로 전달됩니다.


인풋 어셈블러의 출력을 설명하는 구조체를 정의합니다. 동시에 이 구조체는 정점 셰이더의 입력으로 사용됩니다. 인풋 어셈블러가 출력하는 각 정점에 대해 GPU는 하나의 정점 셰이더 스레드를 실행합니다.
첫 번째 정점을 예로 들어 보겠습니다.
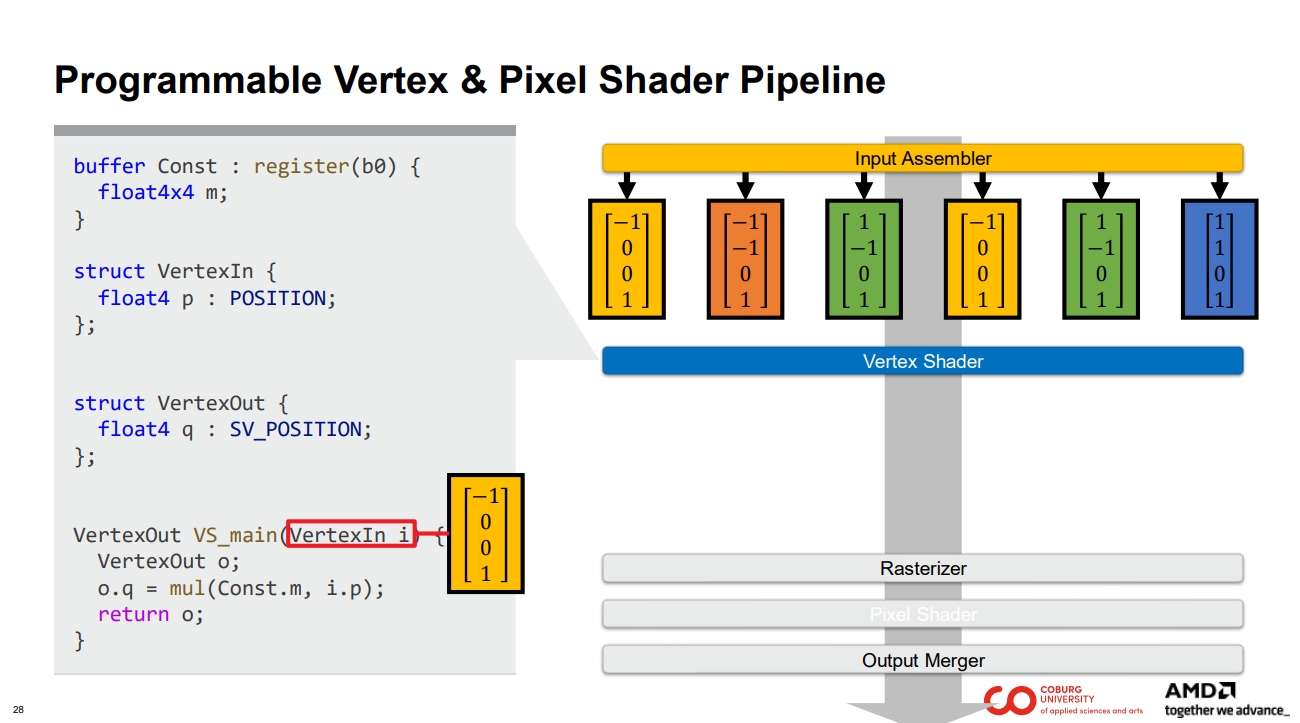
노란색 상자 안의 정점은 하나의 정점 셰이더 스레드에 대한 입력 역할을 합니다.
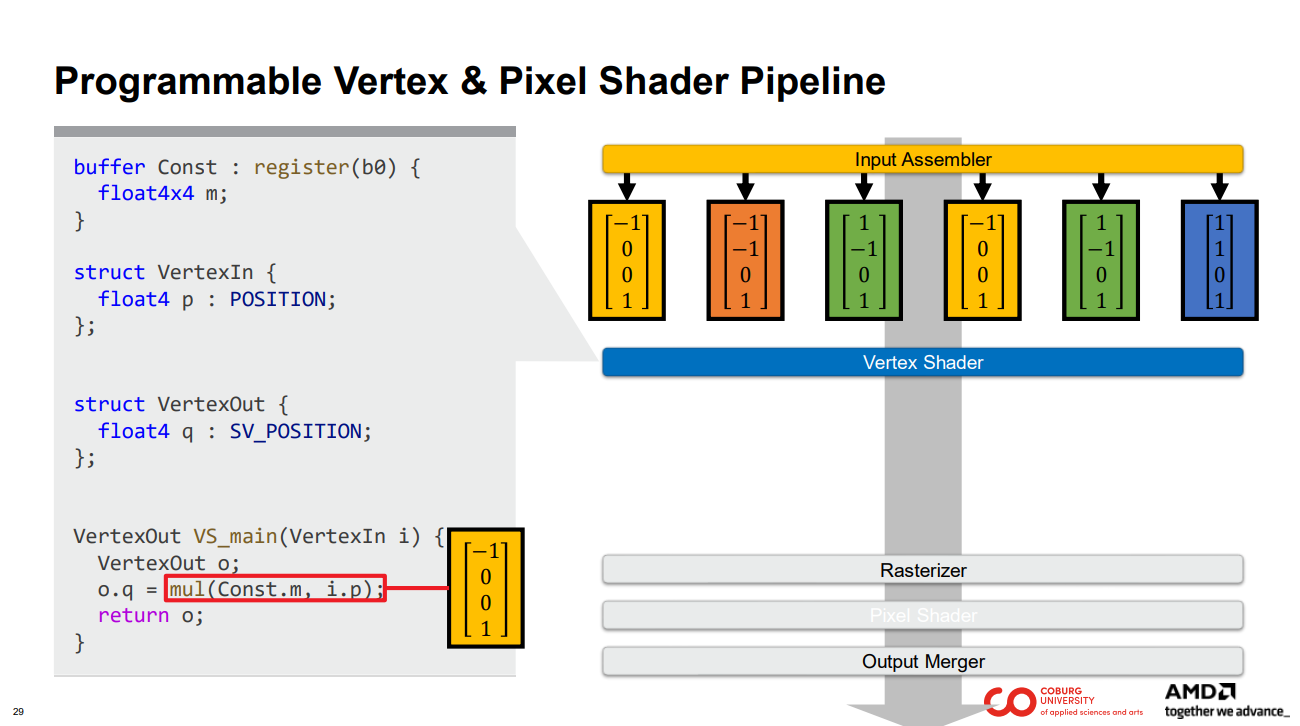
해당 입력을 통해 정점 셰이더 스레드는 프로그래머가 지정한 작업을 수행합니다.
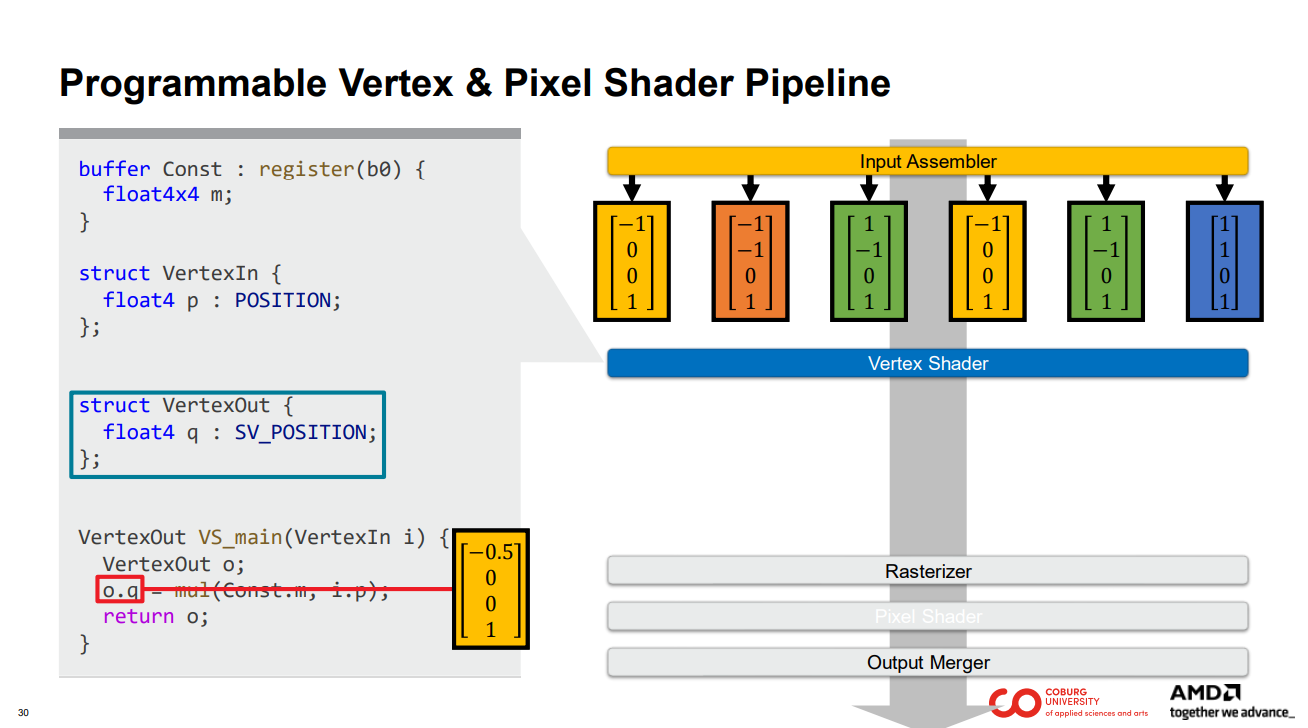
… 그리고 프로그래머가 파란색 상자에 표시된 구조체로 정의한 출력을 작성합니다.

그러면 결과가 정점 셰이더 출력에서 제공됩니다.

다른 모든 정점도 같은 운명을 겪습니다. 즉, 서로 다른 입력을 사용하여 동일한 정점 셰이더 코드를 통과합니다.
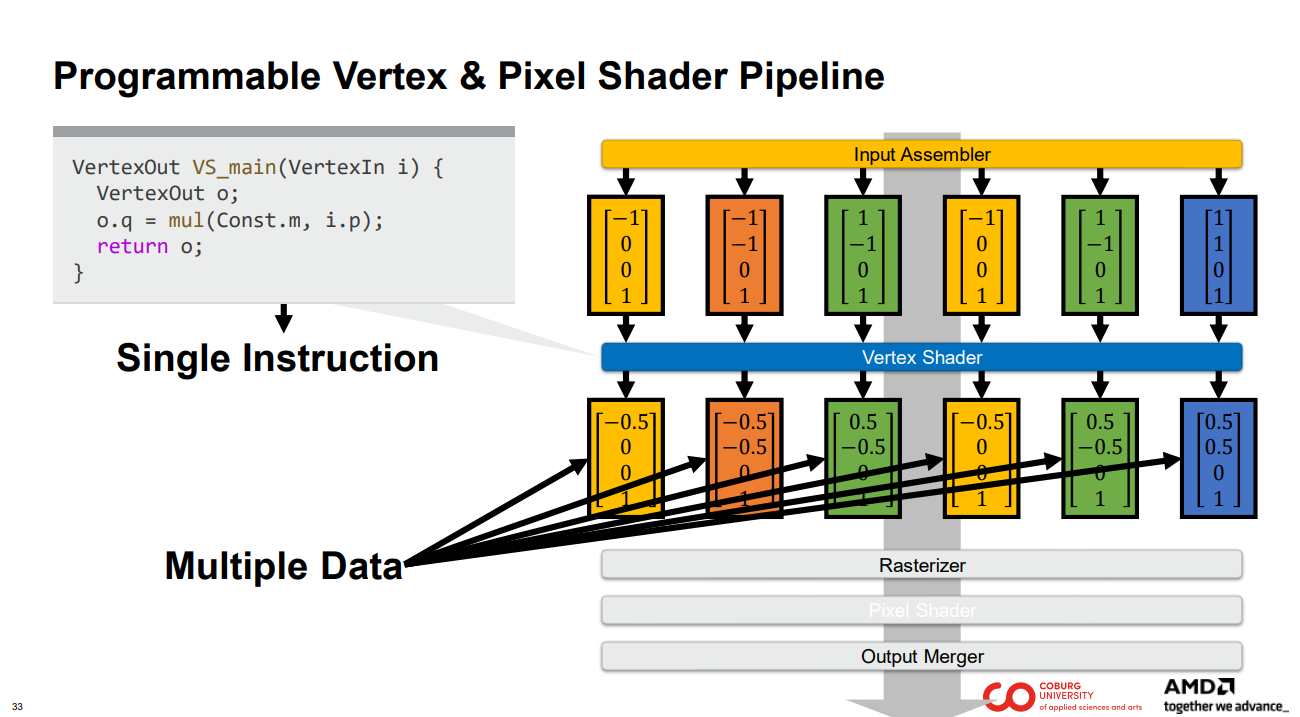
이것은 매우 중요한 개념입니다. 동일한 코드가 서로 다른 데이터 항목에 대해 실행됩니다.
즉, 하나의 명령어(Single Instruction)가 여러 데이터에 대해 동작합니다. 따라서 단일 명령어, 다중 데이터…라는 이름이 붙었습니다.
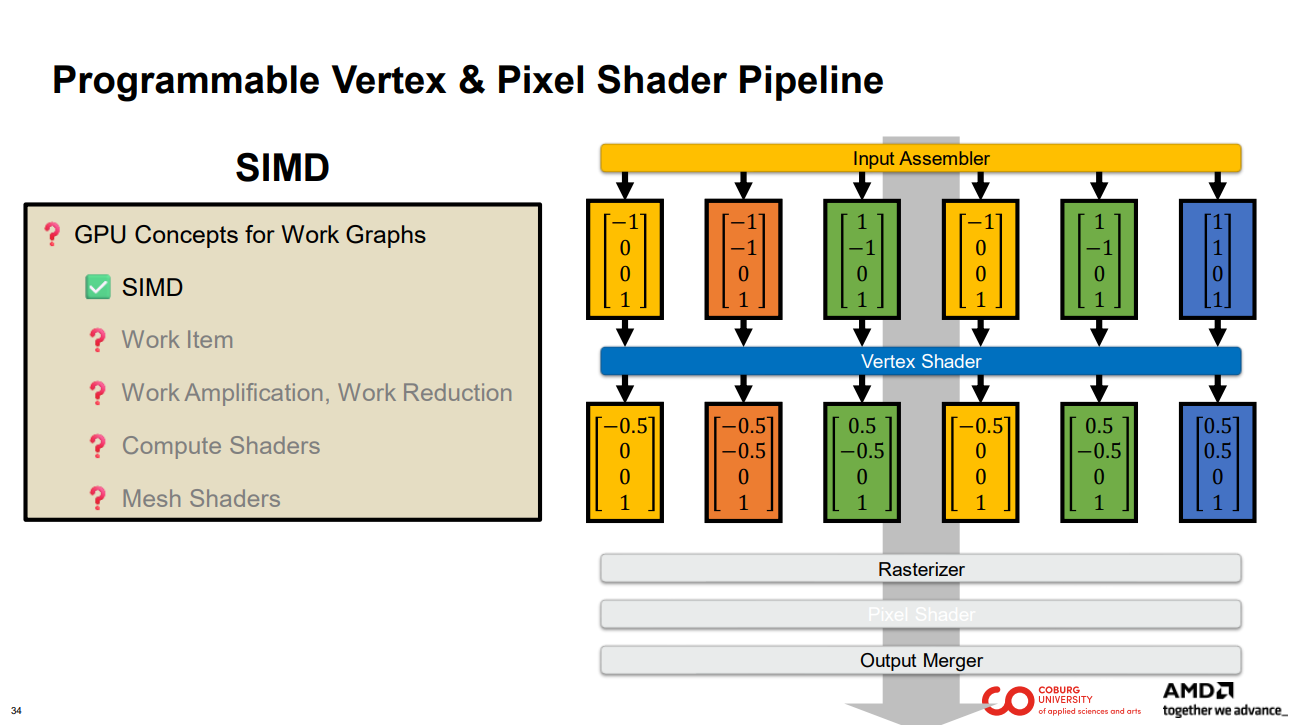
… 또는 줄여서 SIMD라고도 합니다.
SIMD는 GPU의 기본 병렬 컴퓨팅 모델이며, GPU 성능에 매우 중요합니다. 웍스 그래프는 GPU에서 실행되므로 SIMD 모델을 사용합니다.
참고 : GPU와 관련하여, 대규모 병렬 기반 컴퓨팅 모델은 SIMT(Single Instruction, Multiple Threads)라고도 합니다.

추상적인 관점에서 보면, SIMD의 D(데이터)와 같은 정점 속성은 작업 항목(Work Items)입니다.

… 파이프라인을 통해 진행됩니다.
파이프라인에서 한 단계는 생산자 역할을 하고, 그 다음 단계는 소비자 역할을 합니다. 각 단계는 항목을 소비하고 동시에 생산할 수 있습니다.
파이프라인을 통해 흐르는 항목을 작업 항목(work items)이라고 합니다.
이러한 관점에서 볼 때, 그래픽스 파이프라인은 이미 Work Graphs에서도 사용되는 데이터 흐름 지향 모델(data-flow-oriented model)을 제공하고 있지만, 훨씬 더 정교한 방식으로 제공됩니다.
하지만 이미 익숙한 버텍스-픽셀 셰이더 파이프라인으로 돌아가 보겠습니다.
버텍스 셰이더는 방금 버텍스를 변환했습니다.

래스터라이저는 세 개의 정점으로 구성된 튜플을 수집하고 삼각형을 프래그먼트로 이산화(discretizes)5합니다.
이는 작업 증폭(work amplification)으로 볼 수 있습니다. 삼각형을 입력 데이터 항목으로 가정합니다. 이 입력 데이터 항목을 훨씬 더 많은 출력 항목, 즉 프래그먼트로 증폭합니다.

하지만 래스터라이저는 프래그먼트를 생성하지 않는 삼각형을 제거하는 등 작업을 완전히 줄일 수도 있습니다.
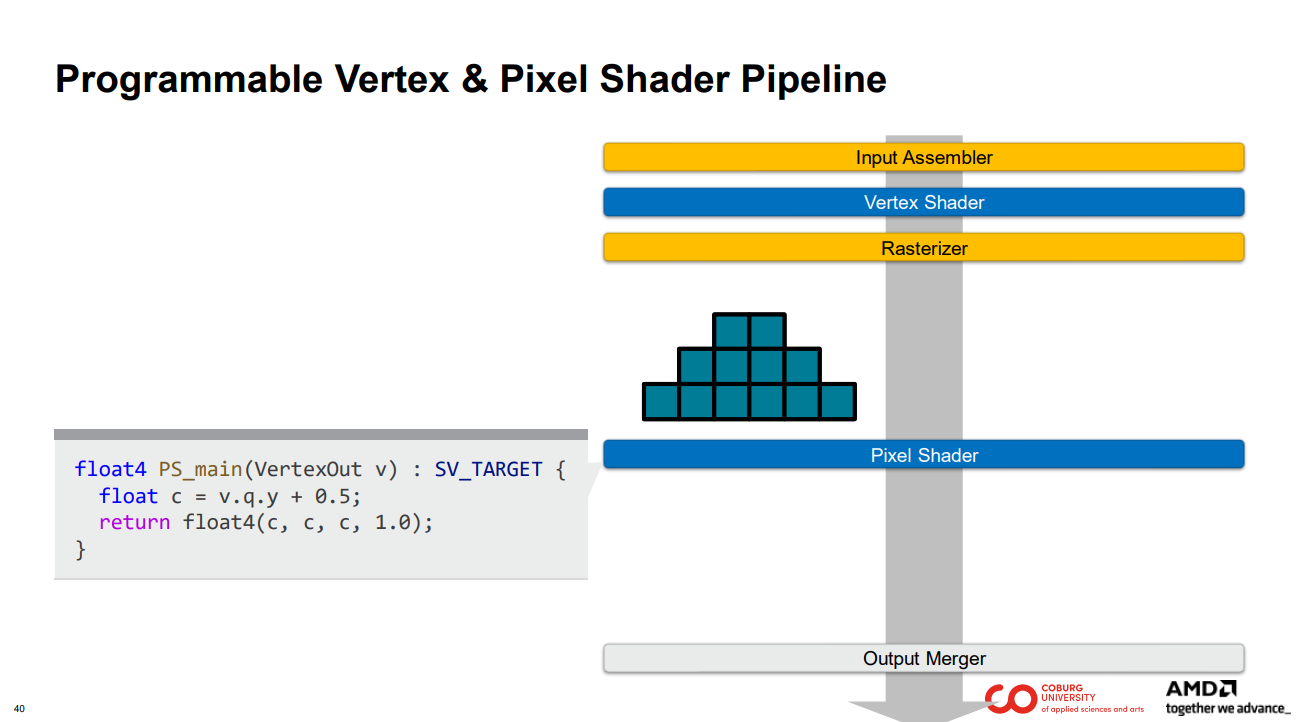
픽셀 셰이더는 다시 SIMD 모델을 사용하는 프로그램입니다. 각 프래그먼트는 입력 작업 항목(input work item)입니다.

…그리고 GPU의 한 스레드에 의해 실행(executed)됩니다…

… 어느 색상이 출력될지 계산합니다.

각 프래그먼트 셰이더 스레드는 출력 데이터 항목을 출력 병합기에 전달합니다.


이것으로 2002년의 버텍스 및 픽셀 셰이더 파이프라인에 대한 이야기를 마칩니다.
Work Graph에 사용할 일부 개념은 당시에도 이미 존재했다는 것을 살펴보았습니다.

파이프라인에는 두 개의 프로그래밍 가능한 스테이지와 여러 개의 구성 가능한 고정 기능 스테이지가 있습니다.

버텍스 셰이더는 버텍스에 대해 SIMD를 사용하고, 프래그먼트 셰이더는 프래그먼트에 대해 SIMD를 사용합니다. 2006년, D3D10은 또 다른 프로그래밍 가능 단계인 지오메트리 셰이더를 도입했습니다. 이 단계는 삼각형 및 기타 기본 요소에 대해 SIMD를 사용합니다.
하드웨어 설계자들은 모든 프로그래밍 가능 단계가 동일한 기본 SIMD 원리를 사용한다는 것을 발견했습니다.

공통된 추상화를 제공하기 위해 통합 셰이더 모델을 만들었습니다.
각 스레드는 셰이더 코어에 매핑됩니다. 여러 셰이더 코어는 하나의 작업 그룹 프로세서로 그룹화됩니다. 예를 들어, AMD RDNA 3 아키텍처에서는 작업 그룹 프로세서당 128개의 셰이더 코어가 있습니다.
작업 그룹 프로세서의 셰이더 코어는 AMD RDNA 3 GPU에서 128KiB의 공유 메모리를 통해 통신할 수 있습니다.

이러한 여러 개의 작업 그룹 프로세서가 GPU에 탑재되어 있습니다. AMD Radeon RX 7800 XT에는 30개의 작업 그룹 프로세서가 있습니다.
작업 그룹 프로세서는 공통 그래픽 메모리를 공유합니다. 현재 이 메모리는 수 GB에 달합니다.

GPU의 추상 모델이 이렇게 완성되었으니, 새로운 셰이더 유형을 정의하는 것은 당연한 일이었습니다. 이를 통해 컴퓨트 셰이더(Compute Shader)가 탄생했습니다.

컴퓨트 셰이더는 GPU 추상화를 필요로 합니다.
공통 그룹 공유 메모리에 접근하는 스레드를 포함하는 셰이더입니다. 스레드는 셰이더 코어에 매핑되고, 그룹 공유 메모리는 공유 메모리에 매핑됩니다.
스레드들은 스레드 그룹으로 클러스터링됩니다. GPU 하드웨어에서 스레드 그룹은 작업 그룹 프로세서에서 실행됩니다.
-
여기서 말하는 Mesh node는 Mesh Shader 단계 전체를 Work Graph의 한 노드로 취급한 개념으로 개별 커널 실행 단위(스레드 그룹 하나)가 아니라, “Mesh Shader 파이프라인 호출”을 그래프의 노드 단위 작업으로 캡슐화 한 것을 말한다. 이 Mesh Node는 Work Graph 내 다른 노드(예: Culling Node, LOD Selection Node, Lighting Node)와 연결되어 데이터 플로우를 형성하게 된다.(works graph 상에서 추상화한 노드)
논문에서 말한 “2024년 3분기에 공개된 Mesh Nodes”는 DirectX 12 Work Graphs의 Mesh Nodes 프리뷰를 이야기하며,. 이때부터 그래프의 리프(leaf) 노드에서 메쉬 셰이더 파이프라인을 직접 실행할 수 있게 되어, CPU 드로우콜 없이 그래프 안에서 바로 렌더링이 가능해졌다.(Microsoft가 Agility SDK v1.715.0 프리뷰와 함께 Mesh Nodes를 공개했고, AMD 라데온 공개 드라이버는 Q3 2024에 Mesh Nodes 지원이 탑재된다고 공지)
https://devblogs.microsoft.com/directx/d3d12-mesh-nodes-in-work-graphs/
기존 Work Graph 노드는 전부 “컴퓨트형”이었는데, Mesh Node는 컴퓨트가 아니라 메쉬 셰이더 기반 그래픽스 파이프라인을 dispatch한다. 즉, 노드 자체가 mesh shader + (선택적) pixel shader + 래스터라이저 상태를 포함한 그래픽스 프로그램(PSO 유사체)로 구성되게 된다. 이로 인해 그래프 내부에서 드로우콜이 1급 시민이 되며, PSO 선택/스위칭과 (옵션) 순서 보장 래스터라이즈까지 지원하게된다. 이로인해 완전한 GPU-driven 파이프라인을 구성할 수 있게 된다.
AMD의 가이드 https://gpuopen.com/learn/work_graphs_mesh_nodes/work_graphs_mesh_nodes-tips_tricks_best_practices/ 에서 이야기하는 주요 내용은 아래와 같다.
1) 작게 쪼개진 디스패치를 합쳐라 : 작은 레코드 다발 대신 코얼레싱 노드나 그룹 출력으로 “한 번에 더 큰 메쉬 디스패치”를 날려 오버헤드를 가린다.
2) PSO 스위칭 최소화 : 가능한 공통 그래픽스 상태를 크게 유지해 스위칭 비용을 줄여라.
3).렌더 타깃 배열: 동일 그래프 내에서 다른 패스(G-Buffer/섀도우 등)를 동시에 그리려면 배열 슬라이스를 활용하라.
[본문으로] -
Indirect Execution : GPU가 실행할 명령(드로우, 디스패치 등)의 파라미터를 메모리 버퍼에서 읽어와 실행하는 방식.
Execute Indirect : DirectX12에서 제공하는 Indirect Execution을 위한 구체적인 API [본문으로] - Amplification Shader (AS) : Mesh Shader 앞에서 실행되어, 몇 개의 Mesh Shader 그룹을 만들지 증폭(amplify).하는 단계를 의미한다 [본문으로]
- Work Graphs에서의 “재귀적 증폭"은 노드가 실행 중에 자기 자신 또는 다른 노드를 새로 디스패치할 수 있다는 의미로 한 노드가 “Amplification 역할”을 하고, 그 결과가 다시 추가적인 Amplification을 발생시킬 수 있다는 이야기이다.
다단계 증폭 (multi-level amplification) : Culling → Binning → LOD → Mesh Node → 또 다른 Mesh Node … 와 같이 계층적으로 증폭 구조를 설계 가능
재귀적 증폭 (self-recursive amplification) : 하나의 노드가 자기 자신을 다시 실행해서 동적 워크로드를 계속 확장 가능 (예: 쿼드트리/옥트리 기반 지형 세분화, 파티클 시뮬레이션, LOD streaming)
그래프 노드가 자기 자신이나 다른 노드를 동적으로 증폭·재귀 호출할 수 있는 일반화된 모델을 이야기 한다 [본문으로] - 연속적인 삼각형을 실제 화면의 불연속적인 픽셀 그리드로 변환하는 과정을 이야기 한다 [본문으로]
'Technical Report > Graphics Tech Reports' 카테고리의 다른 글
| 2025 TA Campus 수업 문서 링크 (0) | 2026.01.20 |
|---|---|
| [번역중]Microflake theory (0) | 2025.07.14 |
| GPU Specification compare PS5/XBOX Series X/Adreno/PC (0) | 2025.05.24 |
| [번역]Forward vs Deferred vs Forward+ Rendering with DirectX 11(2) Deferred Rendering (0) | 2025.05.12 |
| WGSL vs GLSL vs HLSL 문법 차이 (0) | 2025.05.01 |
