이거한번 정리해야지 했던건데 좀 늦게...
SRP Batcher는 Unity의 Scriptable Render Pipeline (URP/HDRP 등)의 퍼포먼스 핵심 기능 중 하나로,
GPU에 바인딩되는 셰이더/머티리얼/상수 버퍼를 효율적으로 처리하는 기능이다.
요구되는 내용은 아래와 같다.
- Uniform Buffer Object (UBO) : 모든 Material 데이터를 UBO 구조로 압축해서 GPU에 보낸다.
- GLSL 구조화된 Layout 지원 : constant buffer layout이 정확하게 일치해야 GPU가 batch 처리 가능
- GPU에 std140 또는 std430 레이아웃 지원 : OpenGL ES 3.1부터 지원(WebGL 지원 불가)
Unity documentation : https://docs.unity3d.com/kr/2023.2/Manual/SRPBatcher.html

DarkCat님의 SRP Batcher와 GPU instancing 성능 비교 : https://darkcatgame.tistory.com/166
std140과 std430은 GPU에서 buffer data의 메모리 정렬 규칙(layout rule)으로, CPU가 버퍼 데이터를 GPU에 넘길 때, GPU는 정확한 위치에 변수 값이 들어 있기를 기대하게 된다. GPU는 정해진 정렬 방식(std140, std430)을 사용해서 데이터를 고속으로 처리하게 되고, Unity SRP Batcher는 UBO 기반으로 머티리얼 데이터를 처리하기 때문에, 이런 정렬 규칙이 필수적으로 요구된다.1
| 항목 | st140 | st430 |
| 사용 가능한 버퍼 타입 | Uniform Buffer (UBO) | Shader Storage Buffer (SSBO) |
| 정렬 방식 | 보수적 (많이 패딩됨) | 효율적 (최소 패딩) |
| 필드 간 간격 | 항상 16바이트로 정렬 | 필요한 만큼만 정렬 |
| 구현 플랫폼 | OpenGL ES 3.1+, Vulkan, Metal 등 | OpenGL 4.3+, Vulkan, Compute 중심 |
std140 Layout rule : GLSL 1.40 이상 버전에서 uniform block 내 변수 정렬을 위한 규칙.
| 변수 타입 | 크기 및 정렬 규칙 |
| bool, int, uint, float, double | 해당 스칼라 타입의 크기와 동일한 크기 및 정렬 |
| 2-컴포넌트 벡터 (예: ivec2) | 스칼라 타입의 2배 크기와 정렬(float는 4B, float2는 8B) |
| 3/4-컴포넌트 벡터 (예: vec3, vec4) | 스칼라 타입의 4배 크기와 정렬(float3는 12B가 아닌 16B 크기를 가진다) |
| 스칼라 또는 벡터의 배열 | 각 요소는 vec4 크기 배수로 정렬되며, 전체 배열의 크기도 이에 맞춰 계산됨 |
| 열 우선 행렬 (column-major) | 각 열이 R개의 컴포넌트를 갖는 벡터 배열로 간주 (총 열 수만큼) |
| 행 우선 행렬 (row-major) | 각 행이 C개의 컴포넌트를 갖는 벡터 배열로 간주 (총 행 수만큼) |
| 구조체 또는 구조체 배열 | 가장 큰 멤버에 맞춘 정렬을 vec4 배수로 맞추며, 전체 구조체 크기도 해당 정렬에 맞춰 패딩 포함 계산됨 |
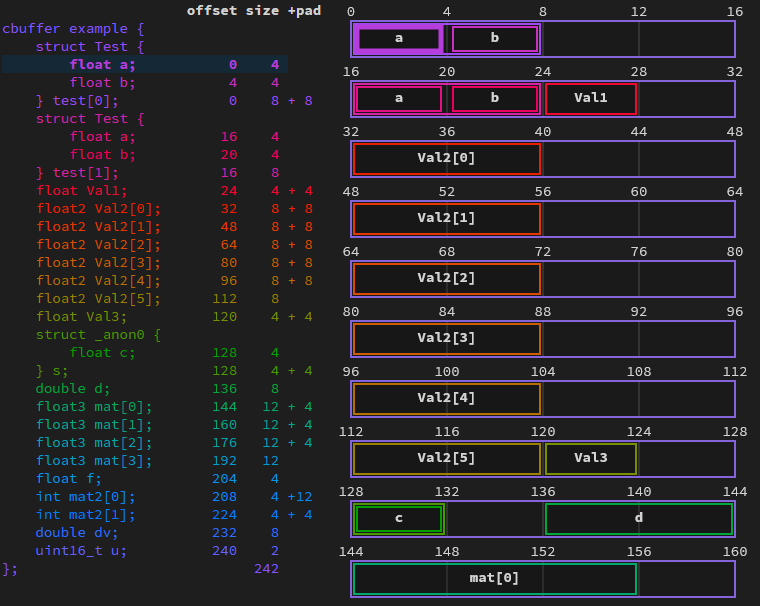
image from : https://maraneshi.github.io/HLSL-ConstantBufferLayoutVisualizer/
따라서 SRP Batcher에서 상수버퍼(Cbuffer)선언시 아래와 같은 규칙을 따라야 한다.
- 데이터 정렬(Alignment) : GPU는 float(4B), float2(8B), float3(16B), float4(16B)를 최소 16바이트 단위로 정렬
- 패딩(Padding) : float3 다음에 float을 넣으면 정렬 오류가 발생할 수 있음.
CBUFFER_START(UnityPerMaterial) float3 myColor; // 16바이트. 정렬상 16B 차지. 아래 주석 참조 float myIntensity; // 바로 붙이면 안 됨! 의도한 위치지만 정렬상 잘못된 배치 CBUFFER_END |
float3(16B) 다음에 float(4B)을 붙이면서 GPU에서 16바이트 정렬 위반. 단순히 크기가 아닌 std140의 구조적 기준에 따라 강제되기 때문에 이런식으로 작성하면 안된다. 표면상 보기엔 총 16바이트라서 padding 이 불필요해 보여도, SRP Batcher에서는 float3가 자체적으로 16바이트 공간을 차지해야 하므로 구조적으로 잘못된 정의.2
CBUFFER_START(UnityPerMaterial) float3 myColor; float _padding0; // 16B 채우기 float myIntensity; float3 _padding1; // 다시 16B align CBUFFER_END or float4 myColorAndIntensity; // myColor.rgb + myIntensity.a ------------------ CBUFFER_START(UnityPerMaterial) float4 _BaseColor; // 16B float4 _MainTex_ST; // 16B float _Cutoff; // 4B float _Glossiness; // 4B float _Metallic; // 4B float _Padding; // 4B → 정렬 맞추기 위해 삽입 CBUFFER_END |
- 변수 순서 맞추기 작은 float 여러 개는 float4로 묶는 걸 고려
- float3 뒤에는 padding 항상 float3 뒤에 float 하나가 오면 padding 필요
- bool이나 int 사용 안됨. CBUFFER에선 float만 권장 (정렬 문제 발생)
- 배열 사용 시 16B 기준 float 배열도 원소마다 16B로 할당됨
CBUFFER는 단순한 상수 값들만 포함해야 하며, Texture2D, sampler, StructuredBuffer 등은 리소스 바인딩용 전용 슬롯이 필요하다.3 4
TEXTURE2D(_MainTex); SAMPLER(sampler_MainTex); CBUFFER_START(UnityPerMaterial) float4 _BaseColor; float _Metallic; float3 _Padding; // padding CBUFFER_END |
SRP Batcher에서 float와 half의 차이
| 항목 | float | half |
| SRP Batcher 처리 | 동일한 정렬 및 패딩 요구 | 동일하게 처리 |
| 메모리 절약 효과 | 없음 (CBUFFER에선 16B align) | 없음 |
| GPU 연산 비용 | 일부 플랫폼에서 차이 있음 | 일부 GPU에서 연산 속도 빠름 |
| Unity CBUFFER 내 의미 | 거의 동일 | 거의 동일 |
CBUFFER는 GPU의 Uniform Buffer Object (UBO) 구조에 맞춰서 std140 정렬 규칙 또는 플랫폼 고정 정렬 규칙에 따라 배치되는데, half, float, int 모두 최소 4바이트 이상 정렬 단위로 배치됨.
half3 → float3와 정렬상 차이 없음 (둘 다 12바이트 + padding)
Unity 내부적으로 CBUFFER 정렬을 float4 단위로 align하기 때문에 half라고 해서 공간 절약이 안 됨
CBUFFER 내의 half는 연산 대상이 아니므로, SRP Batcher에서의 퍼포먼스에 실질적 영향은 없으나 GPU 연산에서는 이득이 있음.
Reference
Unity Disccusion : Clarification on ComputeBuffer.SetData layout requirements?
Unity Disccusion Should I use half3 if color.a is not used?
How SRP Improve Performance : https://blog.csdn.net/kylinok/article/details/131597455
Performance of opengles glBindBufferBase : https://community.khronos.org/t/performance-of-opengles-glbindbufferbase/107860
- SRP Batcher는 std140에 맞춰 UBO 생성하므로 보수적 방식으로 작동한다(padding이 많음) [본문으로]
- Unity 컴파일러에서 변수명이 _padding일 경우 정렬 목적이라는 걸 명확하게 보여주기 때문에 명시적으로 의도하게 된다. 임의로 사용할 경우에는 패킹구조 정렬 목적이 아니라 판단해서 런타임 메모리 레이아웃이 달라질 수 있다 [본문으로]
- CBUFFER는 Uniform Buffer로 GPU의 특정 레지스터(상수 메모리)에 들어간다.(b0, b1, 등) Texture/Sampler는 별도 바인딩 슬롯 (t0, s0, u0)으로 GPU에 전달되게 되므로 레지스터 클래스가 다르기 때문에 한 묶음(CBUFFER)로 선언하면 충돌이 발생한다 [본문으로]
- SRP에서 셰이더와 머티리얼을 바인딩할 때, SetGlobalTexture() / SetGlobalBuffer()를 통해 리소스를 CommandBuffer에 바인딩되며, 정리된 float계열은 CBUFFER로 묶어서 b# 슬롯에 바인딩 된다. Texture/Sampler는 각각 t# / s# 슬롯에 따로 바인딩되게 되는데 이게 가능하려면 Shader 내에서 TEXTURE2D(), SAMPLER()로 선언되어 있어야 한다. [본문으로]
'Technical Report > Unity' 카테고리의 다른 글
| Shader interpolation modifier (0) | 2025.08.29 |
|---|---|
| DXC shader compiler integration (0) | 2025.05.14 |
| Cluster simulation by Compute Shader (0) | 2024.12.31 |
| stochastic tiling shader (0) | 2022.05.29 |
| PBR-BRDF-Disney-Unity-1 (0) | 2022.03.02 |
