PLS(Pixel Logical Storage)와 FBF(Frame Buffer Fetch)의 차이

모바일 플랫폼에서 PLS (Pixel Local Storage)와 FBF (Frame Buffer Fetch)는 렌더링 파이프라인에서 데이터를 관리하고 접근하는 두 가지 서로 다른 방식으로 특히 Deferred Rendering을 효율적으로 렌더링 하는 과정에서 중요하다.
PLS (Pixel Local Storage):

개념 : PLS는 렌더링 중에 픽셀별 데이터를 타일 기반 메모리(주로 GPU의 온칩 메모리)에 로컬로 저장할 수 있도록 해주는 기술로 이는 GPU가 중간 픽셀 데이터를 외부 프레임 버퍼 메모리에 쓰지 않고, 타일 기반 메모리 내에서 로컬로 저장해 처리할 수 있게 한다. 이 방식은 타일 기반 렌더링 아키텍처에 특히 적합한 방법이다.
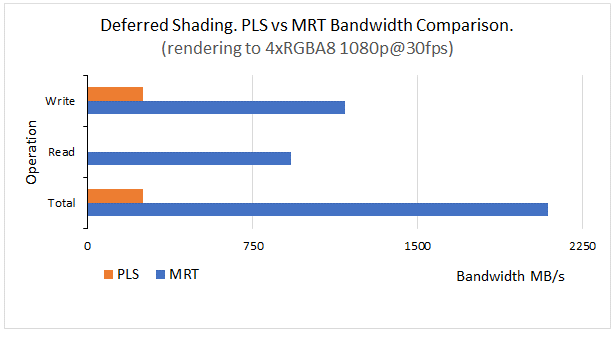
효율성 : PLS는 외부 메모리 대역폭 사용을 크게 줄여주며, 외부 메모리로의 데이터를 자주 쓰고 읽는 과정을 방지한다. 타일 내에서만 데이터를 저장하고 여러 패스에서 재사용할 수 있어, 메모리 트래픽이 줄어드는 이점이 있다. 특히 디퍼드 렌더링에서 여러 번 데이터를 재사용해야 할 때 매우 유용
장점1
- 외부 메모리 대역폭 사용 감소.
- 여러 프레임 버퍼 읽기/쓰기와 관련된 병목 현상을 피할 수 있음.
- 타일 기반 렌더링을 사용하는 모바일 GPU에서 매우 효율적이며, 전력 효율성을 높임.2
단점
- 특정 모바일 GPU에서만 사용 가능 (ARM Mali, Qualcomm Adreno 등 PLS를 지원하는 GPU).
- 온칩 메모리 크기에 의해 저장할 수 있는 데이터 양이 제한적이므로 픽셀당 저장하는 데이터 양을 주의해야 함.

https://community.arm.com/arm-community-blogs/b/graphics-gaming-and-vr-blog/posts/introducing-pixel-local-storage
https://community.arm.com/arm-community-blogs/b/graphics-gaming-and-vr-blog/posts/pixel-local-storage-on-arm-mali-gpus
FBF (Frame Buffer Fetch)
개념 : FBF는 셰이더(특히 프래그먼트 셰이더)에서 현재 픽셀 값을 프레임 버퍼(또는 렌더 타겟)로부터 직접 읽을 수 있게 해주는 기술로 렌더링 중에 해당 픽셀의 이전 결과를 다시 읽어올 수 있으며, 이를 위해 별도의 텍스처나 렌더 타겟이 필요하지 않다.
효율성 : FBF는 주로 셰이더가 이전에 렌더링한 픽셀 데이터를 재사용하거나 후처리할 때 유용하며, 복잡한 데이터 관리 없이 간단하게 프레임 버퍼 값을 다시 가져올 수 있다. 그러나 이 방식은 여러 번의 프레임 버퍼 접근이 필요한 경우 대역폭 문제를 야기할 수 있다
장점
- 이전에 계산된 픽셀 값을 쉽게 읽어올 수 있어 간단한 셰이더 로직에 유리.
- 추가적인 렌더 타겟을 설정할 필요가 없어 코드가 단순화될 수 있음.
단점
- PLS와 비교했을 때 메모리 대역폭을 더 많이 사용할 수 있음.
- 여러 번의 읽기/쓰기 작업이 필요할 경우 성능 저하가 발생할 수 있음.
요약
- PLS는 타일 기반 렌더링에서 픽셀 데이터를 로컬 메모리에 저장하여 메모리 대역폭을 아끼고 성능을 최적화하는 데 유리하지만, 지원되는 GPU에서만 사용할 수 있고 온칩 메모리의 크기가 제한적.
- FBF는 셰이더에서 프레임 버퍼 데이터를 다시 읽어오는 기술로 간단한 접근 방식을 제공하지만, 메모리 대역폭이 더 많이 사용될 수 있어 성능에 영향을 줄 수 있음. 복잡한 블렌딩 연산에서 효율적
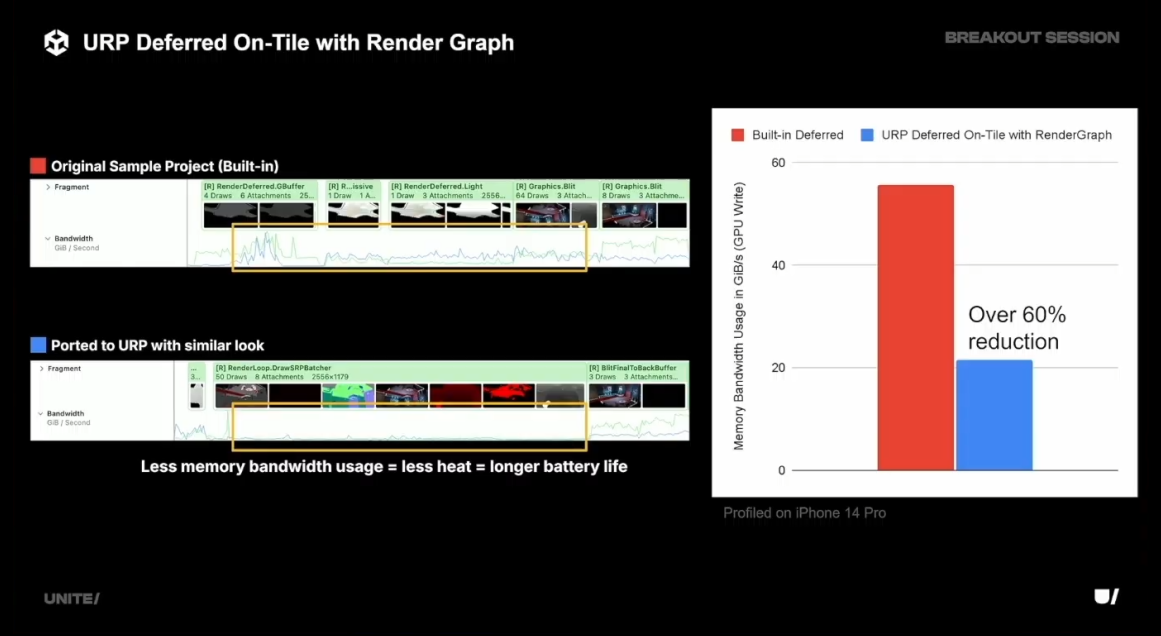

UE 5.1 Review 내용
1. 메모리 대역폭 절감
G-buffer 방식에서는 각 픽셀의 다양한 속성(예: 색상, 법선, 반사율 등)을 외부 메모리에 저장한 후, 이후 라이팅 단계에서 다시 이를 읽어와 조명을 계산한다. 이 과정에서 큰 용량의 데이터를 외부 메모리로 쓰고 읽는 작업이 반복되므로, 메모리 대역폭을 많이 사용하게 된다. 반면, Subpass를 사용하면 중간 데이터를 메모리에 기록하지 않고, 타일 기반 메모리 또는 온칩 메모리에서 직접 조명 계산을 수행할 수 있게되며, 이는 PLS와 결합될 때 더욱 효과적이며, 중간 데이터가 메인 메모리로 가지 않고 GPU 내부에서만 처리되기 때문에 메모리 대역폭 사용량을 크게 줄일 수 있게 된다.
2. 성능 최적화
G-buffer 방식은 다수의 렌더 타겟을 생성하고 이를 읽고 쓰는 과정에서 성능 저하가 발생할 수 있다. 특히 모바일 플랫폼에서는 메모리 접근이 병목이 되는 경우가 많아, 여러 개의 G-buffer를 외부 메모리에 기록하고 이를 다시 읽어오는 과정에서 성능이 저하될 수 있다. Subpass에서는 렌더링의 여러 단계가 연속적으로 처리될 수 있으며, 각 Subpass에서 데이터를 재사용할 때 메모리 접근을 최소화할 수 있다. 따라서 메모리 접근 횟수를 줄여 성능 향상을 기대할 수 있으며, 모바일 GPU의 타일 기반 렌더링에서는 특히 유리한 방식이다.
3. 전력 효율성
모바일 플랫폼에서 메모리 대역폭을 많이 사용하면 전력 소비가 크게 증가하는데, Subpass를 사용하면 외부 메모리 접근을 최소화하므로 전력 소비를 줄이는 데 도움이 된다. [본문으로]- https://community.arm.com/arm-community-blogs/b/graphics-gaming-and-vr-blog/posts/post-processing-effects-on-mobile-optimization-and-alternatives [본문으로]